In part one I blogged about the motivation, and the audience for a data catalog (Atlas). This time I will be talking about the approach, the lay of the land, and hopefully describe the system design and reasons that drove the decisions we made.
Start with the Data
Firstly, looking at the data that we held, it was going clear that there was going to have to be some initial investment of effort in bringing these structured and semi-structured datasets to an indexable catalogue. Some teams (publishers) already had spark processes to “cook” their raw data into formats that were easier to consume such as Parquet. Those were going to be easy to index and provide access to. There were other datasets that would have to br provided as-is for example .tar.gz snapshots of logs and such.
Snapshots versus Mutating Datasets
Some datasets were conveniently presented as snapshots for example daily, weekly, or indeed monthly snapshots… some were even annual snapshots. This implied that we could provide versions of these datasets without fear of presenting the wrong metadata (e.g. filesize) to the user. Mutating datasets would have to be presented with caveats to the consumer.
Metadata, is provided by the data producer. After all, who is best suited to tell us about the data than the person producing it? Some of that metadata we can deduce by reading things like schemas but the ‘softer’ bits of information is best produced by the producer. This can be done at the time the new dataset is being cooked, or when it’s deposited in the publisher bucket. We could have dataset level metadata, or snapshot level metadata. Where both exist, the snapshot level takes precedence.
The data was promarily stored in S3 buckets so we already had a good baseline for the technical considerations we would need to make in terms of permissioning and such. We also have to bear in mind that these teams all had their own AWS accounts and VPCs so we would have to cross over into those VPCs to get their data to our catalog. More on that later.
The presentation
There already existed a CKAN instance that was languishing from lack of updates. It had been through a few heavy custom modifications and so it had become exceeding difficult to update that installation. We would need to either update that or replace it, and make sure we could index the metadata in ways that we could display nicely.
The Plumbing
As I mentioned before teams had their datasets sat in S3 buckets all over the enterprise, and it was our job to aggregate all of these datasets into a coherent UI where consumers could browser for and consume these datasets. The first thing we had to consider was how we could get to those datasets with as little intervention from us and the publishers… we would need to install a function in their account to notify us about changes in those buckets. We would also need to install some IAM permissions for ourselves so that once we are notified of those changes we could then access metadata associated with those datasets and/or analyse that data for additional things such as a data dictionary (more on that later).
For this work we turned to terraform, as most teams had an infrastructure engineer assigned to them and we had a central infrastructure organisation, we could build the terraform modules as we required and distribute those modules to teams we needed to onboard without too many conversations about what we could and could not do… I preface this as always, with the fact that conversations needed to be had with the publishing teams to make sure they understood what exactly need to happen.
We had identified that a majority of our consumers would be consuming these datasets programmatically… so we had to cater to that too. How were we going to provide access to datasets in a publishers account from something like a spark cluster in a consumers account if there were both in different VPCs.
For us the answer was creating roles in our VPC per dataset, and allowing the consumers to assume those roles when they were requesting access to those datasets. Now the IAM roles were then installed into the publishers VPC account as part of the terraform install operation that the publishers team would run.
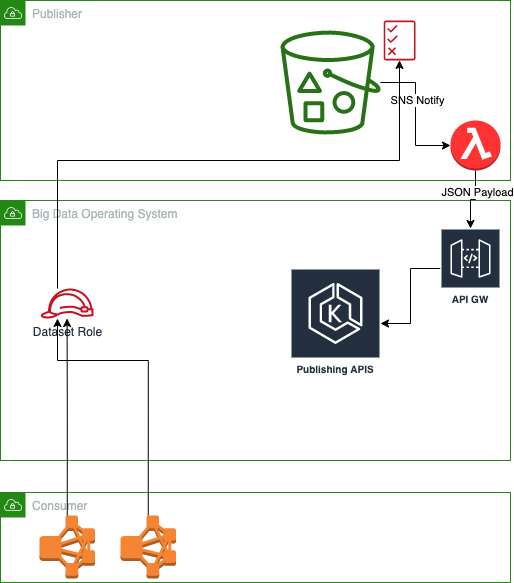
So far the components in red are the new components we create. A dataset role + access policy and a lambda to push notifications to us when the metadata is updated.
The Brokers
In our own VPC we had three APis… One that was responsible for receiving published dataset information, the second was actually a ‘headless’ CKAN installation to handle the indexing, searching, and retrieval of datasets. The third (Atlas) was for everything else. Which included handling dataset requests, presenting data to be rendered by a separate react UI and also a presenting the data layer for moderating the requests made to publishers. This API was also responsible for onboarding publishers onto the system as well. Basically by providing us with minimal information about where their datasets lived, we would be able to run some infrastructure code (through AWS lambda) to provision access to those datasets, and generate a template for publishers' terraform variables.
By integrating the Atlas API into our existing SAML authentication service we were able to leverage concepts such as groups and users from Active Directory for permissions and Authentication. We were also able to queue up commands for lambdas to do things like adding external users to the list of users able to assume roles that had access to the datasets that had been registered and published.
In the next installment I will try and tie this all together with some simple user journeys and a bit more in-depth descriptions of how we put our own infrastructure together to make the user journeys work.
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email